KYC(Know Your Customer)解决「你的用户是谁」,KYT(Know Your Transaction)解决「这笔交易、这个地址干净吗」。对交易所、钱包、支付与合规机构而言,KYT 是反洗钱(AML)合规的核心引擎:在用户充值 / 提现 / 交易的瞬间,判断对手地址是否涉诈、涉赌、涉制裁、与混币器关联,并据此放行、加验或拦截。德尔泰在为平台客户搭建链上风控能力时,KYT 引擎几乎是绕不开的基础设施。这篇就以一线链上风控团队的视角,拆解一套 KYT 引擎该怎么设计。
一、整体架构
一套生产级 KYT 引擎,大致由五个模块组成:数据接入层、标签解析库、图谱关系网、评分计算引擎、规则研判系统。
其中,数据接入负责把多链原始数据「喂」进来;标签库与资金图谱是「关系」与「知识」;风险评分把关系量化成分数;规则引擎把分数翻译成动作。以下是整体流程简图:
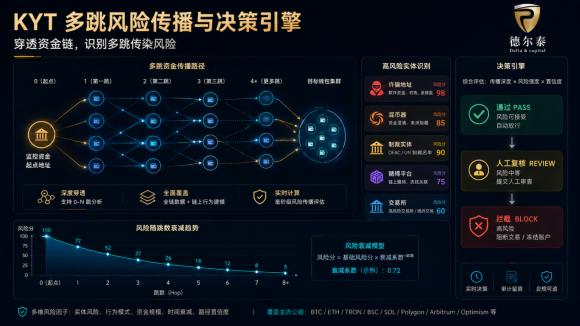
二、数据层:多链接入与地址标签库
多链数据接入:归档全节点 + 浏览器 API + 第三方数据源,覆盖 BTC / ETH / Tron 等主流链与主要稳定币,支持历史状态回溯。
地址标签库:KYT 的「知识」全在标签库里——交易所、混币器、诈骗、制裁名单(如 OFAC SDN)、暗网市场、OTC 等实体标签,每个标签都应带来源、时间、置信度。
德尔泰维护的是一份持续更新的千万级实体标签库,这是 KYT 评分准确性的根基——标签库的质量,直接决定风控的误报率与漏报率。这也是 KYT 难以靠一套开源代码速成、必须长期积累的原因。
三、风险评分模型:风险敞口与传播衰减
核心思想:一个地址的风险,不只看它「自己是不是黑」,更要看它和高风险实体的资金距离。直接和制裁地址交易,风险极高;隔了五跳才间接相关,风险则大幅衰减。
一个可用的评分模型:地址风险分 = Σ(命中标签权重 × 资金占比 × 距离衰减)。
RISK_WEIGHTS = {
"sanctioned": 100, # 制裁名单
"scam": 90, # 诈骗
"darkmarket": 80, # 暗网市场
"mixer": 70, # 混币器
"gambling": 40, # 涉赌
"exchange": 5, # 普通交易所(低风险)
}
def address_risk_score(address, max_hops=5, decay=0.5):
"""
基于资金敞口的地址风险评分(0-100)。
get_exposures 返回 [(风险类别, 资金占比, 距离hops), ...],
由资金图谱 + 标签库 + 污点分析计算得到。
"""
score = 0.0
for category, ratio, hops in get_exposures(address, max_hops):
weight = RISK_WEIGHTS.get(category, 0)
score += weight * ratio * (decay ** hops) # 距离越远,衰减越多
return min(round(score, 1), 100)这里的 get_exposures 正是建立在资金图谱 + 污点分析之上——这也是为什么 KYT 引擎离不开一张高质量的资金图谱。德尔泰的评分引擎在此基础上支持多模型污点分析(Haircut / FIFO / Poison)与跨链续链,让「间接风险」也能被量化。
四、规则引擎:把分数翻译成动作
评分之上是规则引擎,它把「分数」翻译成「放行 / 加验 / 拦截」。规则应当可配置、可审计、可回溯:
RULES = [
{"if": lambda ctx: ctx["risk"] >= 90, "then": "BLOCK", "reason": "高风险:疑似制裁 / 诈骗关联"},
{"if": lambda ctx: ctx["risk"] >= 60, "then": "REVIEW", "reason": "中风险:转人工复核"},
{"if": lambda ctx: ctx["mixer_hops"] is not None and ctx["mixer_hops"] <= 2,
"then": "REVIEW", "reason": "两跳内关联混币器"},
{"if": lambda ctx: ctx["amount"] >= 100000, "then": "REVIEW", "reason": "大额交易"},
]
def evaluate(ctx):
for rule in RULES:
if rule["if"](ctx):
return rule["then"], rule["reason"]
return "PASS", "低风险放行"德尔泰在实战中会按客户的牌照地区、业务类型与风险偏好定制规则集,并保留每一次命中的快照,以备监管审查——合规风控的价值,一半在判断,一半在「可解释、可追溯」。
五、资金图谱:用图数据库做多跳关联
风险评分要「看多跳」,背后就需要一张资金图谱。用图数据库(如 Neo4j)存「地址—交易」关系,支持多跳查询与污点传播:
// 查询某地址 3 跳内是否关联到任意「制裁」标签地址
MATCH path = (a:Address {addr: $addr})-[:SENT*1..3]->(b:Address)
WHERE b.label = 'sanctioned'
RETURN path LIMIT 10德尔泰的资金图谱在此之上叠加了多模型污点分析,不仅判断「是否关联」,还能量化「关联了多少」——这正是出具合规报告与司法证据时的关键区别。
六、实时性与工程挑战
KYT 要在用户点「提现」后的几百毫秒内给出结论,工程挑战包括:
- 预计算 + 缓存:热点地址的风险分预先算好、定期刷新,避免实时全图遍历。
- 流式处理:用消息队列 + 流计算(如 Kafka / Flink)实时消费新区块,增量更新图谱与标签。
- 分级响应:低风险走缓存秒级放行,高风险 / 命中规则才触发深度图遍历与人工复核。
- 多源容灾与限频:不依赖单一数据源,避免接口限频拖垮整条风控链路。
七、德尔泰的 KYT 实践
把上面这套东西做到生产级、并经得起监管审查,是德尔泰的核心能力之一:
- 千万级、带置信度的实体标签库,持续更新;
- 多链覆盖 + 多模型污点分析的资金图谱;
- 可配置、可审计、可回溯的规则引擎;
- 由持证法律专家把技术结论对接合规与司法流程。
对平台客户,这意味着一套「开箱即用」的链上 AML 风控;对个人用户,这意味着遇到地址被风控 / 冻结时,德尔泰能快速定位风险来源,并给出合规处置路径。
八、小结
KYT 引擎的本质 = 高质量标签库 + 资金图谱 + 风险评分 + 规则引擎 + 实时工程。它不是某个炫技算法,而是一套需要长期积累数据与工程能力的体系。德尔泰在这一领域的沉淀,正体现在标签库的广度、污点分析的精度,以及与合规、司法的打通上。
风险与合规提示:本文为技术架构科普,示例代码与权重仅作说明,不构成具体合规方案;落地需结合所在司法辖区的监管要求。涉及账户风控 / 冻结,请通过合法合规途径处理。